|
|
|
|
||
| Previous: Job Farming Facility Up: 5. Optimization for TCAD Next: Levenberg-Marquardt Optimizer | ||||
|
|
|
|
||
| Previous: Job Farming Facility Up: 5. Optimization for TCAD Next: Levenberg-Marquardt Optimizer | ||||
Gradient based optimization strategies iteratively search a minimum of a ![]() dimensional target function
dimensional target function
![]() . The target function is thereby
approximated by a terminated Taylor series expansion around
. The target function is thereby
approximated by a terminated Taylor series expansion around ![]() :
:
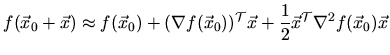
The actual optimization is performed iteratively.
After an initial value
![]() was chosen and the target
function
was chosen and the target
function
![]() was computed, the following loop tries to
achieve a minimum:
was computed, the following loop tries to
achieve a minimum:
To compute the step direction ![]() a linear approximation (first order)
of the target function can be used:
a linear approximation (first order)
of the target function can be used:
This is called the steepest descent method. A second order approach uses a quadratic approximation:
To compute the step width ![]() the parameter vector of the next
iteration is calculated by
the parameter vector of the next
iteration is calculated by
For an analytically given target function the first and second
order derivatives can directly be transferred into a computer program, however
if no explicit formula can be defined, the target is computed numerically by
means of a simulation. In this case approximations for the derivatives are
necessary. In the following the approximation of a univariate target function
![]() is given. For multivariate target functions the finite difference
approximation is applied for each dimension.
is given. For multivariate target functions the finite difference
approximation is applied for each dimension.
The performance of a gradient based method strongly depends on the initial values supplied. Several optimization runs with different initial values might be necessary if no a priori knowledge (e.g., the result of a process simulation) about the function to optimize can be applied.
|
|
|
|
||
| Previous: Job Farming Facility Up: 5. Optimization for TCAD Next: Levenberg-Marquardt Optimizer | ||||