



Vektor- und Parallelrechner
,,Let's use our computers as God intended them to be used.``
[Thus Spake] Gene Golub [Netlib-Newsletter vom 1.12.1991]
Die rasante Entwicklung der Mikroelektronik geht Hand in Hand
mit der Evolution neuer Rechnerarchitekturen.
Die Leistungsfähigkeit
neuentwickelter Rechner ermöglicht
die Anwendung von CAD-Werkzeugen in der Computerindustrie
(horizontales und vertikales Layout, Bauelement-Optimierung
u.v.a.m.), was wiederum den Entwurfs- und
Optimierungskreislauf der Mikroelektronik beschleunigt.
Der weitere Verlauf dieses ,,circulus vitiosus``
der Mikroelektronik ist nicht abzusehen, da eine
Sättigung der Leistungsfähigkeit der neuen
Computergenerationen nicht zu beobachten ist.
1976 wurde der erste Cray-Computer (Cray-1) installiert.
Dieser erste ungemein erfolgreiche Vektorcomputer
hatte ein Zykluszeit von 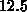 Nanosekunden, was
einen technologischen Meilenstein für diese Zeit darstellt.
Die arithmetische Spitzenleistung (Angabe des Herstellers)
lag bei ca.
Nanosekunden, was
einen technologischen Meilenstein für diese Zeit darstellt.
Die arithmetische Spitzenleistung (Angabe des Herstellers)
lag bei ca. 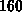 Millionen arithmetischen Operationen
pro Sekunde, also sogenannten Megaflops.
Millionen arithmetischen Operationen
pro Sekunde, also sogenannten Megaflops.
Seit dieser Zeit hat die Supercomputerindustrie einen
stürmischen Aufschwung genommen, deren wichtigste
Exponenten neben der bereits erwähnten Firma
Cray Research die Firmen CDC und IBM und die japanischen
Hersteller Fujitsu
(in Europa z.T. vertreten durch die Fa. SIEMENS),
Hitachi und NEC sind.
Wie auf vielen industriellen
Sektoren hat die japanische Supercomputerindustrie
sich zu einer gewaltigen Konkurrenz für die
lange Zeit marktbeherrschende amerikanische entwickelt.
Die bislang angeführten Computertypen gehören
den sogenannten Vektorcomputern an. Diese
Rechner erreichen ihre hohe arithmetische Leistungsfähigkeit
durch ihre Eigenschaft, Zahlen-Vektoren durch einen
einzigen Vektorprozessor-Befehl zu verarbeiten.
Das steigert den arithmetischen Durchsatz dahingehend,
daß pro Zyklus z.B. gleichzeitig zwei Zahlen aus dem
Speicher geladen, arithmetisch verknüpft und beim nächsten
Zyklus im Speicher wieder abgelegt werden.
Im Gegensatz dazu erreichen Parallelrechner ihre
Leistung durch synchrones Arbeiten mehrerer Prozessoren.
Parallele Architekturen lassen sich grob
und ohne Anspruch auf Vollständigkeit nach ihrer
Speicherorganisation und ihrem Instruktionsschema
klassifizieren. Shared-Memory-Architekturen sind
durch einen gemeinsamen Speicher charakterisiert,
der von mehreren (im allgemeinen wenigen)
Prozessoren benutzt und verwaltet wird. Ein Beispiel
eines solchen Rechners ist die Alliant-FX Klasse
( ,
, 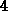 ,
, 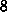 oder
oder 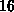 Prozessoren) oder
die VAX-64xx-Reihe.
Prozessoren) oder
die VAX-64xx-Reihe.
Eine gänzlich andere Rechnerarchitektur sind sogenannte
massiv-parallele
Rechner vom SIMD (Single Instruction Multiple Data)-Typ.
In solchen Rechnern kontrolliert eine Zentraleinheit
eine große Menge untergeordneter Prozessoren.
Es existiert kein gemeinsamer Speicher. Der Datenaustausch
der vielen parallel arbeitenden Prozessoren erfolgt
durch ein komplexes Netzwerk von Kabeln (,,wires``).
Ein Beispiel dafür ist die ,,Connection Machine``
der Firma Thinking Machines Corporation.
Im diesem Kapitel werden Implementationen des
Simulators MINIMOS auf solchen Rechnerarchitekturen
vorgestellt und diskutiert.
Die Absicht dahinter ist einerseits, das gewaltige
Potential, das hinter solchen Maschinen steckt, aufzuzeigen,
und neue Wege in der Bauelement-Simulation zu beschreiten.
Andererseits soll die wissenschaftliche Problematik
bei der Entwicklung von Algorithmen speziell für diese
Rechner beleuchtet, Lösungen für bestehende
Probleme angeboten und ungelöste
herausgestrichen werden.