5.3.1 General
ViennaX can be seen as a plugin execution framework. Available simulation tools or
components can be wrapped by plugins and therefore reused. An application is thus
constructed by executing a set of plugins. The input configuration file based on the XML
contains information indicating the plugins to be utilized during the course of the execution.
Additionally, parameters can be provided by this configuration file, which are forwarded to the
respective plugins by the framework.
Plugins can have data dependencies, which are internally represented by a task graph and
handled by the so-called socket system. Different scheduler kernels are available, focusing on
different execution approaches, being serial, task parallelism, and data parallelism,
respectively. These applications can be used to execute the graphs generated from the input
XML file.
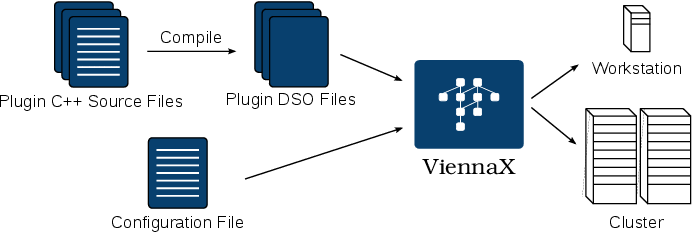
Figure 5.11 schematically depicts the general execution flow of the framework. Plugins
are implemented and compiled as dynamic shared objects ( DSOs), which are forwarded to
the framework’s application. In addition to the plugins, the input configuration file is passed to
the application. The schedulers automatically generate and execute the task graph according
to the data dependencies. The intended target platforms are workstations or clusters, which
are supported by different distributed scheduler kernels based on the MPI. More specifically,
the Boost MPI Library [49] is utilized to support distributed-memory parallelization
(Section 5.1.2). Our approach does not wrap the parallel execution layer of the target platform
like MPICH [152].
As such, the framework is executed as a typical application utilizing the respective
parallelization library. For instance, to execute an MPI capable scheduler application, the
following expression is used.
mpiexec -np 4 ./vxscheduler config.xml plugins/
In this case the mpiexec command spawns the execution of four instances.
vxscheduler relates to the application, whereas configuration.xml refers to the XML input
file holding the required information to build the task graph. The final parameter
plugins refers to the directory path, containing the plugins to be utilized during the
execution.
Different scheduler kernels, those being the serial mode ( SM), distributed task parallel
mode ( DTPM), and distributed data parallel mode ( DDPM) scheduler, as well as the plugin
system and the configuration facility are accessible via an API (Figure 5.12). The API enables
software developers amongst others to implement or adapt schedulers. The design of the
framework allows for different task execution modes implemented by the respective
scheduler kernels to support, for instance, different parallel task graph execution
strategies.
|
|
|
| | Graph Execution | Plugin Execution |
|
|
|
| SM | serial | serial/shared-memory |
|
|
|
| DTPM | distributed | serial/shared-memory |
|
|
|
| DDPM | serial | distributed |
|
|
|
| |
Table 5.1: Overview of graph and plugin execution modes supported by the component
execution framework.
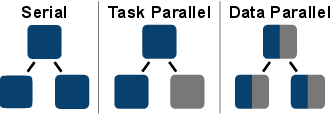
Table 5.1 discusses the available scheduler kernels. The SM-based kernel processes
one plugin at a time, where the individual plugins run either serial and/or parallel
shared-memory-parallelized implementations restricted to a single process, such as OpenMP.
The DTPM kernel models the task parallel concept in an MPI context, where plugins are
executed in parallel by different MPI processes, if the respective dependencies are satisfied.
Consequently, applications with parallel paths in the graph can benefit from such a scheduling
approach, such as the already indicated wave front simulations [149]. Finally, the DDPM
kernel allows for a data parallel approach, where, although each plugin is processed
consecutively, the plugins’ implementation follows an MPI-based parallelization
approach. Such an approach allows, for instance, to utilize an MPI-based linear
solver component within a plugin, such as PETSc [122]. Figure 5.13 schematically
compares the principles of the different execution modes, by mapping components to
vertices
of a graph.
The currently implemented parallel scheduler focus on the distributed MPI. To better
support the ongoing development of continually increasing core numbers per computing
target, scheduler kernels utilizing shared-memory parallelization approaches are
planned for future extensions. These future extensions are supported by the introduced
naming scheme for the scheduler kernels as well as by the applied modular kernel
approach.