
 |
|
||||
BiographyMichael Quell was born in 1993 in Vienna, Austria. He received his Bachelor's degree and the degree of Diplomingenieur in Technical Mathematics from the Technische Universität Wien in 2016 and 2018, respectively. After finishing his studies he joined the Institute for Microelectronics in June 2018, where he is currently working on his doctoral degree. He is researching high performance algorithms and data structures within the scope of the Christian Doppler Laboratory for High Performance TCAD. |
|||||
Shared-Memory Block-Based Fast Marching Method for Hierarchical Meshes
The fast marching method (FMM) is commonly used in expanding front simulations (e.g. fluid dynamics, computer graphics and process simulation in microelectronics) to restore the signed-distance field property of the level-set function. This is also known as re-distancing. To improve the performance of the re-distancing step, parallel algorithms for the FMM, as well as support for hierarchical grids, have been developed; the latter to locally support higher resolutions of the simulation domain while limiting the impact on overall computational demand.
The previously developed multi-mesh FMM has been extended using the block-based FMM approach to enable improved serial and parallel performance on hierarchical grids. This extension introduces a new parameter, maxBlockSize, which splits meshes that are larger than this parameter into smaller ones. The OpenMP paradigm is used for the underlying coarse-grained parallelization on a per mesh basis. The employed approach allows for an improved load balance, as the algorithm employs a high degree of mesh partitioning, enabling one to load balance mesh partitions with varying mesh sizes.
Fig. 1 shows the runtimes for the coarsest level of a sample hierarchical grid for a mandrel structure. The maximal block size of 1000 does not induce any splits in the single mesh and is equivalent to the base code. The coarsest level consists only of a single mesh, therefore no parallel speed up is obtained with this block size. For a block size of 30, the shortest runtime is overed, which used 16 threads. Further decreasing the block size leads to an increase in runtime because the overhead and the number of synchronization steps grows with the number of meshes. In Fig. 2, the runtimes for the finer level of the same structure are shown. Without splits there are already 54 meshes available, the base code therefore scales well until 8 threads. The usage of smaller block sizes enables a small speed up at 8 threads and a significant, better speed up at 16 threads. The lowest runtime is observed at a block size of 75. Also, using a block size that is too small on the finer level deteriorates the performance.
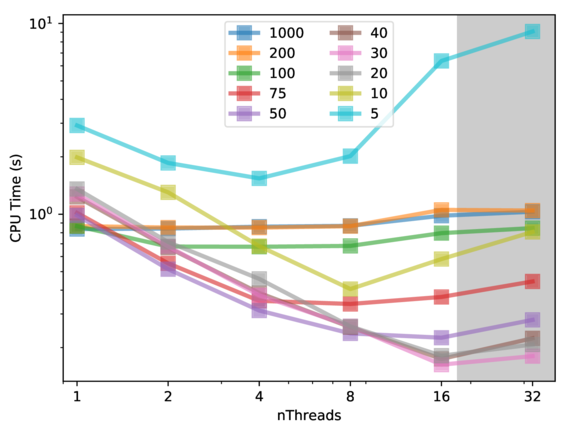
Fig. 1: Runtime for the block-based multi-mesh FMM on the coarsest level for different maximum block sizes by utilizing up to 32 threads on 16 physical cores.
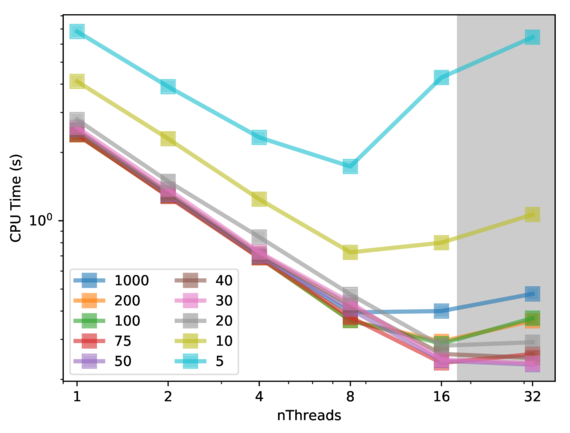
Fig. 2: Runtime for the block-based multi-mesh FMM on the finer level. This approach allows for better scalability for 16 threads compared to the base line code (block size 1000, no mesh is split).