
 |
|
||||
BiographyKarl Rupp was born in Austria in 1984. He received the BSc degree in electrical engineering from the Technische Universität Wien in 2006, the MSc in computational mathematics from Brunel University in 2007, and the degree of Diplomingenieur in microelectronics and in technical mathematics from the Technische Universität Wien in 2009. He completed his doctoral degree on deterministic numerical solutions of the Boltzmann transport equation in 2011. His scientific interests include discretization schemes and massively parallel algorithms in multiphysics problems. |
|||||
Fast Parallel Solvers for Semiconductor Device Simulation
The simulation of charge carriers in semiconductor devices is an important design tool in the continued miniaturization and performance increase in electronics. It allows for a careful optimization of various design parameters without having to run expensive and time-consuming trial-and-error fabrication on delicate equipment. Moreover, simulation enables a better understanding of the underlying physical processes and thus encourages new innovations.
Depending on the actual device at hand, many different simulation methods can be used. Approaches based on the numerical solution of partial differential equations usually require the solution of large systems of linear or nonlinear equations with typically thousands to millions of unknowns. At this scale, it is important to use efficient algorithms and optimized implementations to compute solutions quickly.
Modern solution methods need to make use of the parallel nature of today's processors. The performance of a single compute core on a processor is almost stagnating (Fig. 1), so the only path forward is to make good use of the additional compute power available through parallelism. Ideally, the performance gain is directly proportional to the number of cores. Hence, a 64-core processor computes the solution in 1/64th of the time. In practice, however, it is often challenging to get any performance gain when using more than a single processing core.
In our research, we look into solution methods that make effective use of parallel processors available today. One of the most promising is multigrid methods, where the full solution of a huge system of equations is obtained from a sequence of smaller systems of equations that are faster and easier to solve. We have successfully implemented multigrid methods for massively parallel architectures, such as graphics processing units, in the past and are currently looking into ways to leverage this insight for supercomputers with thousands of processor cores, such as the Vienna Scientific Cluster.
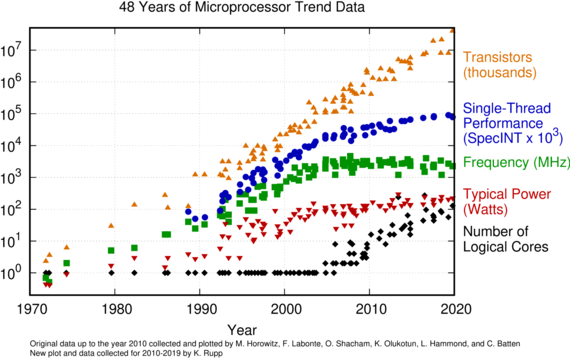
Fig. 1: Microprocessor trend data spanning 48 years. Because of power constraints, clock frequencies have not increased since 2005, limiting sequential performance. Instead, modern processors include additional cores, resulting in the need for parallel workloads.