




The theoretically predicted average complexity
for the boundary refinement is 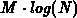 and
the complexity for the actual triangulation is
and
the complexity for the actual triangulation is 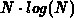 (where
(where 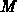 is the number of boundary edges after refinement and
is the number of boundary edges after refinement and
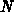 is the number of Delaunay nodes).
is the number of Delaunay nodes).
Figure 6.33 shows the measured
performance of the most important
algorithms. Realistic input data with a variety of geometries and
input grid point clouds have been used. CPU time measurements have been
performed on a DECstation 5000/200, Ultrix V4.3 using the native C compiler.
of the most important
algorithms. Realistic input data with a variety of geometries and
input grid point clouds have been used. CPU time measurements have been
performed on a DECstation 5000/200, Ultrix V4.3 using the native C compiler.

Figure 6.33: CPU time (in seconds) of the gridding process as
a function of the number of triangles generated.
Boundary refinement (Steps 4 and 5), sole triangulation (Step 6)
and total CPU time (including PIF input and output).
It will be shown in Chapter 7 that VORONOI is very efficient so that it may even be called after (or before) almost every simulator to construct a consistent wafer state, without significantly contributing to the total computational effort of practical simulation flows.