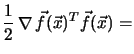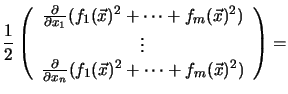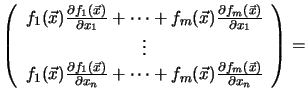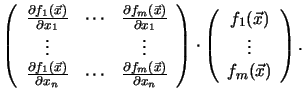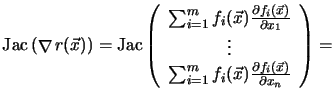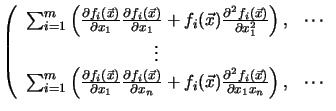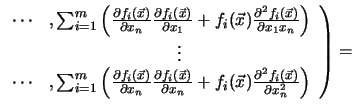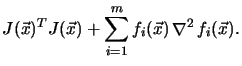The optimization target is to find the best parameter vector ![]() which
gives a minimal residuum vector
which
gives a minimal residuum vector ![]() .
Using the sum of square-roots of
the elements of
.
Using the sum of square-roots of
the elements of ![]() as the target function
the problem can be written as
as the target function
the problem can be written as
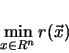 |
(4.27) |
where ![]() is the cost function which is calculated by
is the cost function which is calculated by
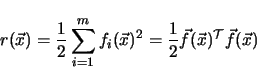 |
(4.28) |
| (4.29) |
This function can be minimized by a general unconstrained optimization method explained in Section 4.4.
From an algorithmic point of view, the feature which distinguishes
least square problems from the general unconstrained optimization
problem is the structure of the Hessian matrix
![]() (see Section 4.1.6).
(see Section 4.1.6).
For differentiable residual vectors
![]() the gradient of the cost function
the gradient of the cost function ![]() can be expressed by
can be expressed by
This can be expressed by the Jacobian matrix ![]() of
of
![]() (see Appendix B.1)
(see Appendix B.1)
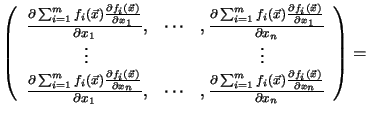
The Hessian matrix
![]() can be
expressed by the Jacobian of the gradient of
can be
expressed by the Jacobian of the gradient of ![]() (the operator
(the operator
![]() builds the Jacobian matrix from a vector function see Appendix B.1)
builds the Jacobian matrix from a vector function see Appendix B.1)
The first term of the Hessian matrix
![]() can be calculated
form the Jacobian matrix
can be calculated
form the Jacobian matrix ![]() only.
This term dominates the second order term for small residuals.
only.
This term dominates the second order term for small residuals.
Using the steepest-descent algorithm the search direction for the next step is given by
| (4.39) |
On the other hand for the Newton direction the linear system given by (4.10) and (4.38)
| (4.40) |
These two strategies for the search direction, Newton direction and Steepest-descent, have different convergence properties and are chosen by considering the target function.
If the quadratic model of the target function is accurate the Newton method converges quadratically to the optimum value if the Hessian matrix is positive definite, the start value is sufficiently close to the optimum, and the step length converges to 1 [19].
Using the steepest-descent algorithm the step of the next iteration is always a descent direction for a non vanishing gradient. In practice, the steepest-descent method typically requires a large number of iterations to make progress towards the solution. Trust region methods (see Section 4.1.8) enable a smooth transition from the steepest-descent direction to the Newton direction in a way that gives the global convergence properties of steepest-descent and the fast local convergence of Newton's method. The Levenberg-Marquardt algorithm uses these properties to solve least-squares problems.