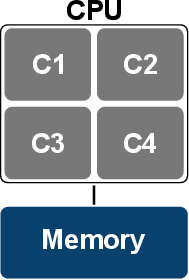
A shared-memory system consists of at least one multi-core CPU1 , sharing the memory available on the system, i.e., all CPUs can access the same physical address space. Examples for such a system are modern single- or multi-socket multi-core workstations. Although, these targets are shared-memory systems, and as such provide a single memory address space to the programmer, the supported memory access patterns vary fundamentally. The most commonly utilized patterns are uniform memory access ( UMA) [100] and cache-coherent ( cc) non-uniform memory access ( NUMA)2 [131]. UMA is typically used by single multi-core workstations, whereas ( cc) NUMA is widely utilized by multi-socket systems. Basically, UMA allows to offer the same access performance to all participating cores and memory locations via a single bus (Figure 5.2).
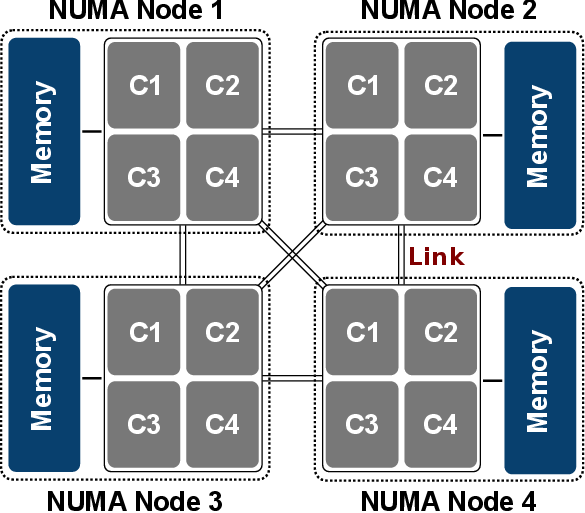
Therefore, UMA systems are also frequently referred to as symmetric multiprocessing systems. Such a symmetric approach does not reasonably scale with the introduction of additional CPUs, as the central bus is quickly saturated. This fact gave rise to the NUMA architecture (Figure 5.3). On NUMA systems memory is physically distributed, but logically shared. A NUMA system consists of several so-called NUMA nodes, typically representing a CPU and its local memory. The NUMA nodes are connected with interconnect links, such as AMD’s HyperTransport or Intel’s QuickPath technology. Consequently, latency and possibly bandwidth between the cores vary depending on the physical location (also called NUMA effects).
From a software point of view, usually - but not exclusively - thread-based approaches are utilized on shared-memory systems. Several approaches are available, such as OpenMP [132], Intel Cilk Plus [133], and Pthreads [134]. Although thread-based programming is considered to be rather intuitive and easy to get used to, it is exactly this feature which makes it hard to achieve reasonable scaling for high core numbers. One of the challenges is the shared-memory approach, i.e., all threads can access the same memory address space. Although convenient, it does not inherently force the developer to handle memory locality, thus NUMA effects easily arise, significantly reducing the scalability. Also, a typical problem with shared-memory approaches is over-utilization, meaning that significantly more threads conducting computations are executed concurrently than CPU cores are available. Obviously severe over-utilization, for instance, more than three times, leads to considerably reduced execution speeds, thus needs to be avoided.