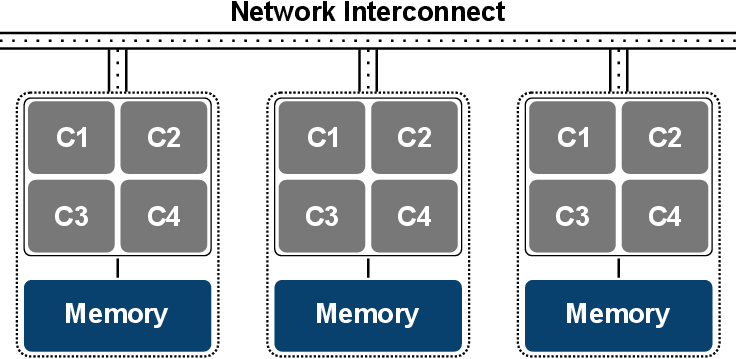
5.1.3 Hierarchical (Hybrid) Systems
Today’s supercomputers and clusters are primarily hierarchical systems, also called hybrids.
Such systems denote a mixture of systems based on different parallel memory models
(Figure 5.5). The most prominent example are supercomputers with shared-memory
nodes
interconnected via a network. Therefore, hybrids are neither purely shared nor are
they purely distributed, further contributing to the challenge of parallel software
engineering.
In fact, hybrids may be utilized by solely applying a distributed programming model, but
hybrid models are supported as well, such as MPI in tandem with OpenMP. A typical approach
is to utilize MPI for inter-node communication, and a shared-memory approach, e.g., OpenMP,
on the individual nodes.
If the node’s infrastructure offers a NUMA architecture, it may become a viable option to
assign several MPI processes to a node and pin one, for instance, to each CPU
socket .
For example, for each socket an MPI process can be assigned rather than using one MPI
process for the whole node. On the right platform, such an approach reduces NUMA
effects. Another considerable aspect is the node’s memory-core ratio, where the
sweet-spot
in today’s systems is typically around 1-2 GB/core. Therefore, using one MPI process for each
core might become challenging with memory intensive applications, as a node might not offer
enough memory to accommodate a given problem. This becomes evident when considering a
typical node setup used in current cutting-edge supercomputers, such as Titan [141],
which is based on single-socket nodes offering a 16-core CPU and 32GB of shared
memory. If 16 MPI processes are executed on such a node, each MPI process
has access to merely 2GB of memory. A ratio of one is provided by the Sequoia
supercomputer, offering 16 compute cores and 16GB of system memory on each
node [142]. The observed node setups also depict an interesting fact based on the
continued microprocessor scaling: a single CPU can now hold up to 16 compute cores,
allowing to build cheaper single-socket nodes rather than the significantly more
expensive multi-socket systems. This enables to remain cost efficient by simultaneously
providing high core numbers. This trend towards higher core numbers per CPU is likely
to continue [143]. At this point it becomes evident that due to the high degree of
anisotropy of the available parallel target platforms, developing reasonably scaling
software for such platforms is one of the major challenges today and especially in the
future [144].