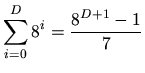|
|
|
|
Previous: 3.4.1.6 Iterators Up: 3.4 Core Data-Structure Layer Next: 3.4.3 Jump-and-Walk |
|
|
|
|
Previous: 3.4.1.6 Iterators Up: 3.4 Core Data-Structure Layer Next: 3.4.3 Jump-and-Walk |
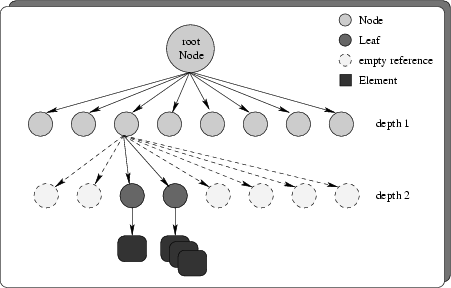
An oct-tree is a data structure to perform three-dimensional point locations and range
searches. In a finite oct-tree the geometrical data are presorted in a way that
allows efficient element searches. The space containing a grid is recursively
decomposed into ![]() sub-spaces. A sub-space can either be a node or a terminal
leaf. A node is an intermediate sub-space that does not contain any elements
itself but serves as a container for other sub-nodes or sub-leafs. A terminal
leaf represents a situation where a further split would not reduce the number of
elements in at least one of the resulting sub-leafs (Fig. 3.12).
sub-spaces. A sub-space can either be a node or a terminal
leaf. A node is an intermediate sub-space that does not contain any elements
itself but serves as a container for other sub-nodes or sub-leafs. A terminal
leaf represents a situation where a further split would not reduce the number of
elements in at least one of the resulting sub-leafs (Fig. 3.12).
The effort to search for an element in an oct-tree is of order
![]() which gives the best possible performance among the two point location methods
presented in this thesis. This nearly optimal search performance is due to the
drastic recursive decomposition of space in
which gives the best possible performance among the two point location methods
presented in this thesis. This nearly optimal search performance is due to the
drastic recursive decomposition of space in ![]() sub-spaces respectively. For
homogeneous grid density, every search step reduces the remaining elements to
search by a factor of
sub-spaces respectively. For
homogeneous grid density, every search step reduces the remaining elements to
search by a factor of ![]() .
.
The major disadvantages of a finite oct-tree are time consuming
pre-processing and memory overheads. The pre-processing time is related to the
algorithm that inserts elements into the oct-tree. For every grid element it must
be decided to which (already existing) sub-node it belongs. This results in a
large number of geometrical predicates that have to be computed until the final
sub-space, the so-called terminal leaf, is found. Furthermore, if a grid element
collides with a terminal leaf, this leaf must be replaced by a node and all
elements of that leaf have to be re-distributed over the newly created
sub-spaces. Depending on how the elements are shaped and how they fit into
already existing leafs the complexity of such a test can vary significantly. In
case one of the points is contained within a leaf the test is reduced to a
simple point compare operation. In the worst case the orientation of several
tetrahedrons has to be computed. Every inserted element traverses all nodes
until it reaches the terminal leaf. On every node level all sub-spaces that
overlap the element must be computed. For each overlapping sub-space the
algorithm recurses into the node or leaf associated to the sub-space. For a
homogeneous grid the majority of grid elements will only overlap one sub-node in
any given level. Thus the amount of overlap decisions per element can be
estimated to ![]() where
where ![]() is the depth of the oct-tree.
is the depth of the oct-tree.
Obviously the memory overhead results from the nodes and terminal
leafs that hold the data. For an average depth ![]() of the oct-tree the number of
nodes and leafs results to:
of the oct-tree the number of
nodes and leafs results to:
To give an example lets compute the memory consumption including the overhead to
store a number of
![]() homogeneously distributed tetrahedrons on a
homogeneously distributed tetrahedrons on a
![]() bit machine. The average depth
bit machine. The average depth ![]() is given as
is given as
![]() . According to (3.1) the number of nodes and leafs computes to
. According to (3.1) the number of nodes and leafs computes to
![]() . This is of the same magnitude as the number of elements
that are stored. A tetrahedron as it is stored in the oct-tree consists of
. This is of the same magnitude as the number of elements
that are stored. A tetrahedron as it is stored in the oct-tree consists of ![]() point references (handles, c. f. Chapter 3.7.1), thus the per
tetrahedron memory consumption is
point references (handles, c. f. Chapter 3.7.1), thus the per
tetrahedron memory consumption is ![]() bytes. If we estimate an average of
bytes. If we estimate an average of ![]() tetrahedrons that share a point we have a total of
tetrahedrons that share a point we have a total of
![]() points
in our example. A point coordinate is stored as an IEEE754 double precision
floating point number that takes
points
in our example. A point coordinate is stored as an IEEE754 double precision
floating point number that takes ![]() bytes. The memory needed to store the data
is then
bytes. The memory needed to store the data
is then
![]() megabytes for the tetrahedrons and
megabytes for the tetrahedrons and
![]() megabytes for the points, which gives a total of
megabytes for the points, which gives a total of
![]() megabytes.
megabytes.
A node consists of ![]() references to sub-nodes or leafs and two
references to points, which amounts to
references to sub-nodes or leafs and two
references to points, which amounts to ![]() bytes of memory. The last of the
bytes of memory. The last of the
![]() layers in the oct-tree structure always consists of leafs, thus the total
number of nodes in our example is
layers in the oct-tree structure always consists of leafs, thus the total
number of nodes in our example is
![]() which gives a memory
consumption of
which gives a memory
consumption of
![]() megabytes. For the remaining leafs (
megabytes. For the remaining leafs (
![]() ) the memory consumption depends on the type of the leaf. Every leaf stores
two point references. Additionally, the smallest leaf stores a reference to one
element, the largest holds an arbitrary number of references. To make a guess
we assume that the medium number of stored element references is three. The
average memory consumption per leaf is then
) the memory consumption depends on the type of the leaf. Every leaf stores
two point references. Additionally, the smallest leaf stores a reference to one
element, the largest holds an arbitrary number of references. To make a guess
we assume that the medium number of stored element references is three. The
average memory consumption per leaf is then
![]() bytes and the total
amount of memory for the leafs is
bytes and the total
amount of memory for the leafs is
![]() megabytes. The total of the
introduced memory overhead in this example amounts to
megabytes. The total of the
introduced memory overhead in this example amounts to ![]() megabytes. If we
relate the memory for the data to the introduced overhead it gives
megabytes. If we
relate the memory for the data to the introduced overhead it gives
![]() . The number of overlap tests is also quite impressive, it can be
estimated to be in the order of
. The number of overlap tests is also quite impressive, it can be
estimated to be in the order of
![]() .
.
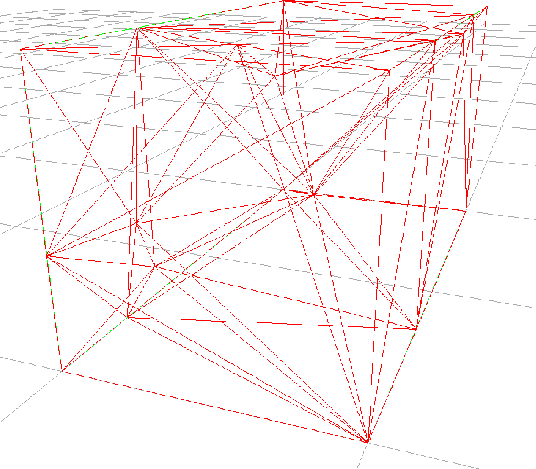
A finite oct-tree that implements the decomposition algorithm was developed at the Institute for Microelectronics [28]. The methods used to determine whether an element overlaps a leaf are encapsulated in an interface. This allows arbitrary elements to be governed by the oct-tree as long as they implement this interface. Fig. 3.13 and Fig. 3.14 depict a small mesh and the resulting leaf structure in the finite oct-tree.
There is also a parallelized version of this algorithm [47,48] available that distributes sub-trees over various networked computers to utilize several CPUs. For communication between the computers the high-level protocol CORBA [49] was used. CORBA is a standard that allows to call methods of remote objects. The location of the object is thereby transparent to the client. The connection between client and remote (server) object is established via an object reference. The references of objects are managed by the CORBA nameserver. The client contacts the nameserver upon startup and requests a reference to a certain object. Such a high-level protocol imposes a considerable overhead compared to a local function call. The overhead is observed as a time delay or as a maximum number of method invocations per second. The delay is closely related to speed and workload of the underlying network infrastructure.
The efficiency of the parallelization is determined by the time delay and the remote CPU time that is consumed by the remote method. If the relation between delay and CPU time is low, or -- in other words -- if a complex remote computation takes place, then the overhead can be neglected. This is the case for the fairly time consuming oct-tree insert method. During the implementation it turned out, however, that the serialization and dynamic instantiation of objects that is necessary to transfer an object (like, e.g. a point) over the network is not well supported in the target language (C++) and imposes an extra programming overhead for each element type. This is in the contrary to the design of the single-threaded oct-tree which is capable of storing arbitrary elements without the need to recompile the oct-tree source code.
Future developments will focus on a multi-threaded version of the oct-tree where only CPUs on one machine can be utilized.
The decision whether an application uses the oct-tree or rather the jump-and-walk algorithm presented in the next section strongly depends on the amount of point locations that will be performed during the simulation. Fig. 3.13 and Fig. 3.14 show a grid of a cuboidal region and the resulting sub-division into nodes and leafs.
|
|
|
|
Previous: 3.4.1.6 Iterators Up: 3.4 Core Data-Structure Layer Next: 3.4.3 Jump-and-Walk |