5.2 Parallelization approaches for Monte Carlo simulation
Monte Carlo code is often termed embarrassingly parallel as a high parallel efficiency is easily achieved in general: If the
particles of an ensemble are independent of each other, smaller subensembles can be handled by separate computational
units
without the need for further communication. The results of the subensembles are later merged to yield the global solution. An independent computation necessitates
that the entire simulation domain is available on each computational unit.
The parallelization of the Wigner Monte Carlo code, however, is complicated by the annihilation step, which hinders the independent treatment of subensembles for two reasons: i)
The annihilation step must be performed on the entire (global) ensemble of particles since (here) the subensembles are not regarded to be big enough to be statistically
representative .
The latter necessitates some communication and/or synchronization between the computational units.
The second obstacle the annihilation step presents to parallelization is ii) the exorbitant memory demands of the annihilation algorithm when treating
higher-dimensional problems. Although the alternative sort-based annihilation algorithm (Section 4.3.3) effectively avoids this problem, the faster, conventional
algorithm is considered here, in the spirit of high-performance computing this chapter follows. The annihilation step requires the phase-space to be represented in the
memory using an array of integers, each storing the sum of particle signs inside one cell (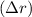 d
d d′) of the phase space grid. While for one-dimensional
simulations the memory footprint of this array remains small, the memory consumption grows rapidly for higher-dimensional simulations. Consider a 2D spatial
domain of 100nm × 100nm with a resolution of Δx = 1nm and a 3D k-space with 100 k-values per direction. The associated phase-space grid would consist of
1002 × 1003 cells, each represented by an integer of (at least) 2 bytes. This would demand a total memory consumption of
d′) of the phase space grid. While for one-dimensional
simulations the memory footprint of this array remains small, the memory consumption grows rapidly for higher-dimensional simulations. Consider a 2D spatial
domain of 100nm × 100nm with a resolution of Δx = 1nm and a 3D k-space with 100 k-values per direction. The associated phase-space grid would consist of
1002 × 1003 cells, each represented by an integer of (at least) 2 bytes. This would demand a total memory consumption of 
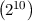 bytes, i.e.
approximately 20GB. A higher resolution increases the memory demands dramatically because they grow to the power of
bytes, i.e.
approximately 20GB. A higher resolution increases the memory demands dramatically because they grow to the power of 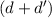 , as discussed in
Section 4.3.2.
, as discussed in
Section 4.3.2.
The need for synchronization/communication amongst subensembles and the high memory demands of the annihilation algorithm make the parallelization of a
Wigner Monte Carlo code much more challenging than other Monte Carlo codes. Possible parallelization approaches are evaluated in the following with reference to
the architectures introduced in Section 5.1.
5.2.1 Shared-memory
In a shared-memory setting the particle ensemble is partitioned amongst the threads and only a single instance of the simulation (the domain and all subensembles)
exists in memory and all threads have shared access to it. The communication required to perform the annihilation on the global ensemble is thereby avoided to a
major extent, but a synchronization amongst the threads is still needed. By using appropriate parallel loop-scheduling techniques the computation load can be well
balanced amongst the threads, which ensures that no thread is left idle for long periods of time before the annihilation is performed on the global
ensemble.
Although simple to implement, a pure shared-memory approach is confined to a single computation node with a limited number of CPU
cores and memory. The latter restricts the simulation problems that can be investigated, based on acceptable run-times and the memory
demands of the simulation. Especially the high-memory demands of the annihilation algorithm limit the simulations to large-memory
nodes ,
which are less prevalent in shared computation facilities.
Therefore, a pure shared-memory approach is best suited for small-scale parallelization cases.
5.2.2 Distributed-memory
A large-scale, MPI-based parallelization approach, is not restricted by the computational resources of a single node, thereby considerably expanding the scope of the
simulations, which can be handled from a computational point of view. The particle ensemble is split into many subensembles, each of which is assigned to a separate MPI
process for
computation. It is more challenging to dynamically react to computational load imbalances amongst processes, compared to the loop-scheduling techniques for
threads available with OpenMP. However, physical insight into the problem and experience can help mitigate this disadvantage.
5.2.2.1 Domain replication
Since the processes do not share a single memory space, the simulation environment must be replicated for each process; this is referred to as domain replication. Due
to the high memory demands of the annihilation algorithm domain replication – as is common for classical Monte Carlo simulation – is problematic in a
distributed-memory environment: Today’s large-scale clusters typically provide between 2 - 4GB of memory per CPU core. If each process is
assigned to one CPU core – this is desirable for an optimal utilization of the computational resources – the memory available to each process
(2 - 4GB) can be insufficient for a complete representation of the phase-space array in multi-dimensional problems (20GB in the example presented
before).
One possibility to circumvent this problem is using a large-memory node to perform the annihilation of the global particle ensemble. In such a case, the
subensemble of every process must be communicated to the master node at each time step, where they are all combined and the annihilation
step is performed. If a sufficient number of worker processes are in operation, the communication bandwidth of the master process’ node will
quickly saturate – the worker processes remain idle while waiting for all other processes to complete their communication and, thereafter, for
the annihilation step to be completed. The post-annihilation particle ensemble is split up again and distributed amongst the processes. All
this communication severely impacts parallel efficiency. Indeed, without domain replication, achieving good parallel efficiencies becomes more
challenging.
5.2.2.2 Domain decomposition
An alternative to domain replication is domain decomposition, which entails splitting up the simulation domain amongst the processes. Each process represents a
subdomain (i.e. a part of the global domain) and only handles particles, which fall within its own subdomain. Thereby, the memory requirements to represent the
(localized) phase-space, as well as all other space-dependent quantities, are scaled down with the number of processes (subdomains) used. This makes the approach
very attractive to large-scale parallelization as it avoids the problems of the aforementioned approaches, i.e. a large memory footprint, centralized communication and
limited scalability/accessibility.
In light of the above, the domain decomposition approach is found to be best-suited for a future-proof parallelization of the WEMC method and its implementation is
discussed in the remainder of this chapter.