The separation of access to data structures and algorithms by means of iterators has become one of the key elements for the generic programming paradigm. Thereby the implementation complexity of algorithms and data structures is significantly reduced (see Section 4.2.3 for more details). But the traversal mechanisms and data access is combined, making a formal interface between data structures and algorithms difficult.
The concise separation property given by the fiber bundle concept states that the only interface between base space and fiber space is focused on a topological identification mechanism, which finds an actual implementation as a cursor and property map concept [110] in the C++ STL5.1. This topological identification mechanism is usually implemented by simple integer numbers.
The following source snippet is an example of this mechanism:
![\begin{lstlisting}[frame=lines,title={Cursor and property map concept}]{}
val = ...
...ue
pmap(*cursor,val); // storing a value
++cursor; // traversal
\end{lstlisting}](img680.png)
Compared to the STL operation realized by iterators:
![\begin{lstlisting}[frame=lines,title={C++ STL iterator concept}]{}
val = *iter; // accessing
++iter; // traversal
\end{lstlisting}](img681.png)
Based on the generic data structure specification and the fiber bundle concepts which haven been introduced, the following formal classification can be obtained:
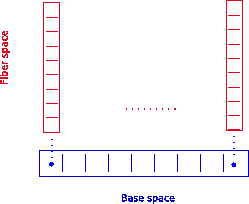
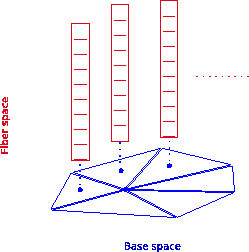
The decomposition of the base space is modeled by the concept of a CW-complex, realized by data structures. As an example, Figure 5.10 depicts on the left an array based on the concept of a fiber bundle. Attached to each cell, marked with a dot in the figure, a simple fiber with several sections is shown which conserves the neighborhood of the base space and carries the data of the array. Another example is given in Figure 5.10 on the right where the base space is modeled by a two-dimensional triangular cell complex.
|
|
| Figure 5.10: Left: a fiber bundle over a 0-cell complex. Right: a fiber bundle over a 2-cell complex. | |
Organizing data by means of fiber bundles separates properties of the base space (which usually is given by a manifold, but more general topological spaces are possible as well) from the properties of the fiber space. The advantage from the software design view is that both properties can be implemented independently. The same mechanisms can be used to access a vector field given on a tetrahedral mesh, a structured grid, or on a particle set.
For the base space of lower dimensional data structures, such as an array or singly linked list, the only relevant information is the number of elements determined by the so-called index space. Therefore most of the data structures do not separate these two spaces. For backward compatibility with common data structures the concept of an index space depth is introduced. As can be seen in Figure 5.11, common data structures can be modeled with an index space depth of zero, such as arrays and lists where the content is directly stored at the given location, e.g., an address. An index space depth of zero means that the location of the data structures addressed by an index, e.g. container[0] can be used directly as the corresponding value. An index space depth of one or larger means that the index value returned has to be used in another container, e.g., a fiber. In other words, the stored content is only an indirection, e.g., an address of a memory location, which has to be dereferenced to obtain the content. The cursor and property map concept always model an index space depth of one.
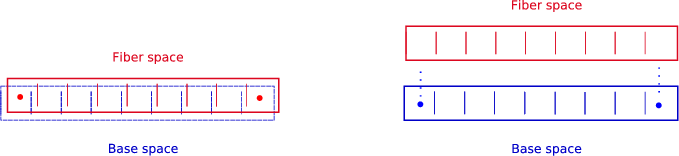 |
| Figure 5.11: Illustration of an index space depth of zero (left) and one (right). The base space is modeled by a 0-cell complex. |
The advantages of this approach are similar to those of the cursor and property map but differ in several details. The similarity is that both properties can be implemented independently. But the fiber bundle approach equips the quantity space with more structure, e.g., storing more than one value corresponding to the traversal position as well as preservation of neighborhoods. This feature is especially useful in the area of scientific computing where different data sets have to be managed, e.g., multiple scalar or vector values on vertices, faces, or cells. Based on the structure of the fiber space, vertical and horizontal subsets (sections) can be extracted.
Another important property of the fiber bundle approach is that an equal (isomorphic) base space can be exchanged with another cell complex of the same dimension. The concept of an index space depth ensures backward compatibility of all data structures in the same context as higher dimensional data structures, such as grids and meshes. The following table summarizes the common features and the differences between cursor and property map and fiber bundles:.
| cursor and property map | fiber bundles | |
| isomorphic base space | no | yes |
| traversal possibilities | STL iteration | cell complex |
| traversal base space | yes | yes |
| traversal fiber space | no | yes |
| data access | single data | topological space |
| fiber space slices | no | yes |
| backward compatibility | no | yes |