| | |
The question may arise: why bother with complexities of theory, when a “just implement it” approach seems to suffice? Here it is essential to note that while an implementation is certainly possible with only a minimum of understanding regarding anything of the underlying problem, the implementation will follow exactly these minimal lines of understanding of the implementer. Following the principle of Occam’s razor 1 , the implementation is bound to be crude and primitive, which in itself is not an undesirable quality if this simplicity is accompanied by easy readability and maintainability. The problem begins to arise, when alterations, however small they may initially appear, to such an implementation are required, which transcend the initial understanding of the programmer. The resulting rigorous redesign incurs the problem that any shortcomings (bugs) already addressed in the previous version may be reintroduced in the new incarnation. While the knowledge of the theory governing the models being implemented can not be regarded as a guarantee that no redesigns become necessary, since this would also indicate a stagnation of the evolution of programming techniques, the lack of such information is bound to result in erroneous, because uninformed, design decisions.
By accepting theories at a high level of abstraction for implementation, more information is accessible on the partitioning of algorithms into modules and components. The lower the level, the less choice is available or required, depending on the point of view. From a point of superior knowledge, which is in theoretical aspects offered by a higher degree of abstraction, complications arising on a purely low level description often in a difficult to classify manner may be avoided or at least quickly identified.
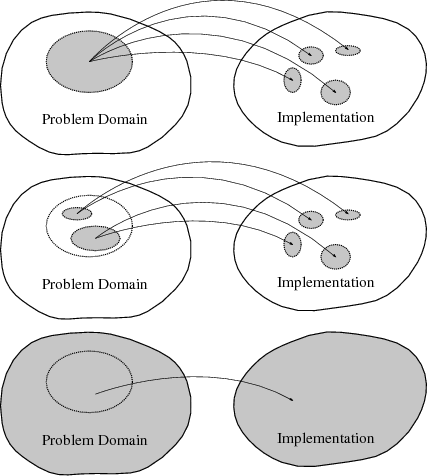
Figure 2.1 illustrates different procedures to transfer a problem from its theoretical domain to an implementation. The marked areas indicate the facilities available and used in each of the different cases.
The top most part of the figure indicates a problem with a well defined theoretical domain, where the implementation can not maintain cohesion as a single entity, but shatters into different, distinct entities. This is a common approach for straightforward implementations using a low level of abstraction. An abstract problem is squeezed directly into machine abstractions including low level information such as memory layouts and architecture specializations. The resulting code is tailored to fit exactly one problem on one platform / architecture; reusability is not considered in such an approach. Examples for this mapping include vectors and tensors which are directly mapped to arrays and matrices.
In the center part of Figure 2.1, the theoretical description itself is split to reduce the level of abstraction, and again mapped to a low level implementation. This can be seen as the low level implementation infecting the theoretical setting to reduce the level of abstraction. Hence the overall level of abstraction is even lower than before, since abstractions are sacrificed on both sides and consequently less of the available capabilities can be utilized. Continuing the previous example, this situation occurs when theory is no longer formulated in terms of vectors and tensors, but torn apart into components in an ill-conceived attempt to make implementation easier.
The bottom figure indicates the goal advocated here and which should be strived for. It aims to make the whole instrumentarium of abstractions in the theoretical domain available by embedding the problem at hand into a larger context. At the same time the implementation is not a priori restricted, as a mapping of the extended theoretical setting is strived for. By embedding the task at hand into the bigger setting on both sides, more choices regarding implementation are made available or at least no venues restricted. The procedure does not preclude to specialize any chosen implementation, as long as it fits into the available abstractions. Thus, abstractions increase the number of choices and hence flexibility. On the other hand, it requires the effort of understanding the problem in its context using a minimum of abstract thought. This also results in a responsibility to choose from the offered selection, which may be perceived as a burden. Again picking up the previous example of vectors and tensors, the choices are no longer as clear cut as before. The theoretical setting now concerns itself with the questions of what a vector or tensor is, what concepts the entities model, such as the algebraic structure (see Section 4.2) of tensors and can also easily encompass specializations such as symmetry considerations. At the same time low level concerns of implementation, such as memory layout or endianness, are no longer the main focus, such that, e.g., vectors may be represented by lists, arrays, or whatever data structure can meet the requirements imposed by theory. The resulting increased amount of choices allows to select different specializations for different contexts of the same implementation, such as a change of the underlying hardware. In this fashion generic programming is not primarily concerned with a single solution, but in providing many easily interchangeable components, which allow for flexibility and reusability of any developed code. The price here of course is a higher investment into the abstraction and design process, which while often frowned upon, is exactly in line with the mantra of top down design.
| | |