


| | |
While it is mathematically sufficient to state a random number follows a specific probability density distribution function (Definition 100), this needs to be explicitly taken care of in a computing settings. The deterministic nature of digital computers is in stark contrast to any required randomness which therefore has to be introduced in an explicit manner. Specialized hardware devices which generate random numbers using various physical phenomena described by statistical means are among the available solutions to this issue. It is, however, also desirable to have a workable algorithmic solution. The reliance on a deterministic algorithm results in certain deficiencies of the generated numbers, as the algorithmic description is directly opposed to the concept of randomness. It thus also becomes necessary to consider the exact requirements the generated random numbers have to meet. This of course depends on the field of application, such as Monte Carlo methods or cryptography. In the context of simulations, the efficient, high performance generation of random numbers is as much a concern as the knowledge of the deficiencies. The exact reproducibility of a pseudo random sequence, which constitutes a mortal sin in the field of cryptography [141][142], is not only perfectly acceptable in the context of Monte Carlo methods, where it may actually be considered a boon, as it eases the development and debugging of algorithms.
The pseudo random sequences generated in an algorithmic fashion experience a period after which the sequence repeats itself. Applications utilizing any such sequence need to be aware of this limitation and should accomplish their calculations before the period is exhausted [143].
Furthermore, care has to be taken, if multiple pseudo random generators are used in order to avoid erroneous results due to unchecked correlations in the generated sequences. This issue is of increased significance due to the general trend towards parallelization [144].
The generation of sequences of pseudo random numbers depends on the desired probability density distribution function. Since it is impractical to provide a pseudo random generator for any conceivable probability distribution function, a possibility to derive pseudo random sequences with differing probability density functions from one another is highly desirable.
One way to accomplish this is using the basic expression


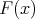 to be invertible, which is not only a theoretical restriction, but may also pose computational
challenges.
to be invertible, which is not only a theoretical restriction, but may also pose computational
challenges.
As inversion may not be a viable course of action, different procedures have been developed such as the
rejection technique, which is also called the rejection sampling method or Neumann’s method. Using
an input pseudo random variable 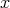 of an available distribution
of an available distribution 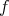 , it calculates a pseudo
random number
, it calculates a pseudo
random number 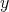 of an arbitrary output distribution
of an arbitrary output distribution 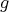 . For this task it requires a rejection
and acceptance rule
. For this task it requires a rejection
and acceptance rule 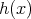 , which determines, if a pseudo random number
, which determines, if a pseudo random number 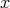 is viable or
not. In case the rule is met, the random number with the desired distribution is calculated
using
is viable or
not. In case the rule is met, the random number with the desired distribution is calculated
using

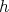 .
.
When the desired probability distribution function 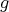 is representable in the form
is representable in the form

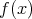 is the input probability distribution density function connected to a variable
is the input probability distribution density function connected to a variable 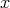 and
and 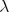 a
bounded function
a
bounded function

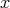 according to
according to 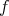 .
.
 – usually the distribution is chosen to be uniform .
– usually the distribution is chosen to be uniform .

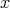 as a realization of a random variable distributed according to
as a realization of a random variable distributed according to 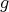 . Otherwise, reject
. Otherwise, reject 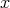 and
restart the procedure.
and
restart the procedure. | | |