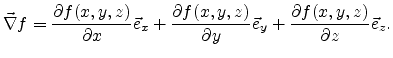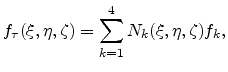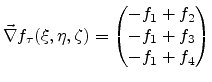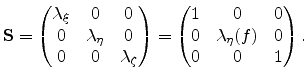In Section 3.2 the so-called layer refinement method was
presented. For this method the solution of the Laplace equation was used as
approximation of the surface distance field and an element grading
example was shown, where mesh elements are mostly isotropic. Now the
layer refinement method is extended by introducing a primary stretching
direction. This direction is aligned to the direction of the gradient field of
the initial scalar data field stored on the mesh. This yields the name
gradient refinement method.
With the help of linear weighting functions, it is possible to
calculate the gradient of a given scalar data field on a tetrahedral mesh element.
It is in the nature of this approach, that the gradient is constant over the
element (vector data ![]() -face relation, cf. Figure 3.1(b) and
Figure 3.2(d)) and varies from element to element, so the gradient
field is piecewise constant.
-face relation, cf. Figure 3.1(b) and
Figure 3.2(d)) and varies from element to element, so the gradient
field is piecewise constant.
The gradient
![]() grad
grad![]() of a scalar field
of a scalar field
![]() in
Cartesian coordinates is given by
in
Cartesian coordinates is given by
Using linear weighting functions on the three-dimensional unit simplex, which are given by Equation (3.6), discussed in Section 3.1.3, allow a linear approximation of the scalar field over the element in the form
However, for the
gradient refinement method the basic idea is to use the gradient of a given
scalar data field stored on the initial mesh to define an anisotropic
refinement metric. This metric is used for an anisotropic tetrahedral bisection
process as described in Section 2.3.1 and Section 2.3.2. If
the gradient given by Equation (3.15) vanishes completely, the
gradient is set to
![]() .
.
As seen in Section 2.3.1, a three-dimensional tensor-based metric
function
![]() can be defined as a combination of rotation matrix
can be defined as a combination of rotation matrix
![]() and dilation matrix
and dilation matrix
![]() . The idea is
to use the direction of the gradient field as the primary stretching
direction. The dilation factor itself is dependent on the initial
scalar data field, stored on the mesh. For this refinement method the
dilation function is defined slightly differently compared to the
layer refinement method, described in the previous section
(cf. Equation (3.11)):
. The idea is
to use the direction of the gradient field as the primary stretching
direction. The dilation factor itself is dependent on the initial
scalar data field, stored on the mesh. For this refinement method the
dilation function is defined slightly differently compared to the
layer refinement method, described in the previous section
(cf. Equation (3.11)):
One can see that now only
![]() depends on the scalar data
field
depends on the scalar data
field ![]() stored on the initial mesh.
stored on the initial mesh.
![]() and
and
![]() are set to unity and there is no dilation with respect to the
are set to unity and there is no dilation with respect to the
![]() - and
- and ![]() -direction.
-direction.
As second step, a directional dependence is introduced by rotating the dilation
function so that the ![]() -direction is parallel to the direction of the
gradient field of
-direction is parallel to the direction of the
gradient field of ![]() . To accomplish this task one first has to rotate
the three axes of the Cartesian coordinate system
. To accomplish this task one first has to rotate
the three axes of the Cartesian coordinate system
![]() in the way that the new
in the way that the new ![]() -axis is
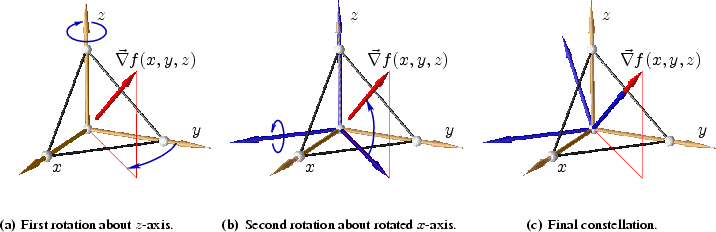
parallel to the gradient vector. The evolution of this rotation is illustrated
in Figure 3.9, where the gradient vector
-axis is
parallel to the gradient vector. The evolution of this rotation is illustrated
in Figure 3.9, where the gradient vector
![]() was
calculated on a standard
was
calculated on a standard ![]() -simplex. The rotation matrix
-simplex. The rotation matrix
![]() can be
easily calculated with Euler rotation angles, see Appendix B.1 for a
detailed description.
can be
easily calculated with Euler rotation angles, see Appendix B.1 for a
detailed description.
 |
For the dilation function
![]() different features are cogitable. One
method is to use the same functional dependence as described in
Section 3.2, where the dilation is scalar data dependent, i.e.
different features are cogitable. One
method is to use the same functional dependence as described in
Section 3.2, where the dilation is scalar data dependent, i.e.
![]() . But one has to keep in mind that the main
difference here is the introduction of a primary stretching direction,
i.e. that only the
. But one has to keep in mind that the main
difference here is the introduction of a primary stretching direction,
i.e. that only the ![]() -axis, which is after the rotation parallel to the
direction of the gradient field, related dilation factor
-axis, which is after the rotation parallel to the
direction of the gradient field, related dilation factor
![]() is
functional dependent. All other dilation factors
is
functional dependent. All other dilation factors
![]() and
and
![]() are set to unity as depicted in
Equation (3.17).
are set to unity as depicted in
Equation (3.17).
In the following an example is given where for the dilation function a
dependence of an initial scalar data distribution ![]() is
introduced. Here again the data function
is
introduced. Here again the data function ![]() is normalized to unity and the
same function as depicted in Figure 3.6 can be used for
is normalized to unity and the
same function as depicted in Figure 3.6 can be used for
![]() .
.
In this example a combination between the layer refinement method described in
Section 3.2 and the gradient refinement method is chosen. The refinement itself is based
on the anisotropic tetrahedral bisection algorithm presented in
Section 2.3.2, Table 2.2.
The idea of this example is to produce a fine anisotropic mesh near a
particular surface of the mesh domain. The finer region should be limited to a
layer with a particular thickness. Isotropic elements should be oriented so
that a high mesh density, i.e. edges of short Euclidian length, arises
perpendicular to the surface, other directions should be mostly
untouched. Figure 3.10(a) show the initial structure where a cubic body
(colored green) is covered with an L-shaped mask (colored blue).
![\begin{figure}
% latex2html id marker 2857
\setcounter{subfigure}{0}
\centering
...
...tion.]
{\epsfig{figure=pics/GRM-iso.eps2,height=0.4\textwidth}}
\end{figure}](img261.png) |
For the construction of the dilation function
![]() , we first solve
the Laplace equation, on the initial coarse mesh domain,
considering the given appropriate boundary conditions as
depicted in Figure 3.10(b). Only the
upper part of the cubic body, not covered by the mask, and the opposite
boundary hold Dirichlet boundary conditions. The Dirichlet conditions are set
as follows: the not covered upper part is set to unity and the opposite plane
is set to zero. All other boundaries hold Neumann boundary
conditions. The solution of the Laplace equation is the scalar field
, we first solve
the Laplace equation, on the initial coarse mesh domain,
considering the given appropriate boundary conditions as
depicted in Figure 3.10(b). Only the
upper part of the cubic body, not covered by the mask, and the opposite
boundary hold Dirichlet boundary conditions. The Dirichlet conditions are set
as follows: the not covered upper part is set to unity and the opposite plane
is set to zero. All other boundaries hold Neumann boundary
conditions. The solution of the Laplace equation is the scalar field
![]() , iso-levels of
, iso-levels of ![]() , and the corresponding gradient field
, and the corresponding gradient field
![]() are shown in Figure 3.10(c) and
Figure 3.10(d), respectively. Note that the gradient field is
orthogonal to the iso-levels.
are shown in Figure 3.10(c) and
Figure 3.10(d), respectively. Note that the gradient field is
orthogonal to the iso-levels.
The next step is to define the dilation function
![]() in dependence
to the solution of the Laplace equation
in dependence
to the solution of the Laplace equation ![]() in the form
in the form
![]() . As noticed in the preamble of this section, the
refinement should cover only a small surface layer with a well defined
thickness. This task was already matter of the layer refinement method, described in
Section 3.2. The same function as
depicted in Figure 3.6 for the dilation function
. As noticed in the preamble of this section, the
refinement should cover only a small surface layer with a well defined
thickness. This task was already matter of the layer refinement method, described in
Section 3.2. The same function as
depicted in Figure 3.6 for the dilation function
![]() is
used. Now the dilation function matrix which is given by
Equation 3.17 is completely specified.
is
used. Now the dilation function matrix which is given by
Equation 3.17 is completely specified.
For the three-dimensional anisotropic tetrahedral bisection algorithm,
described in Section 2.3.2, a metric function
![]() must be
specified which is given by a dilation function matrix
must be
specified which is given by a dilation function matrix
![]() and
an additional rotation matrix
and
an additional rotation matrix
![]() since
since
![]() . The rotation matrix can be easily
constructed by the rotation evolution depicted in Figure 3.9, so
that the new
. The rotation matrix can be easily
constructed by the rotation evolution depicted in Figure 3.9, so
that the new ![]() -axis is parallel to the gradient vector, which is the
sine qua non of the gradient refinement method.
-axis is parallel to the gradient vector, which is the
sine qua non of the gradient refinement method.
Finally, for the anisotropic tetrahedral bisection algorithm an edge refinement
criterion, as shown in Table 2.2 and Table 2.3,
respectively, has to be specified . Here again (cf. Section 3.2) we
use simply an upper limit for the anisotropic length of all mesh edges, so that
all edges are refined which overshoot this maximum.
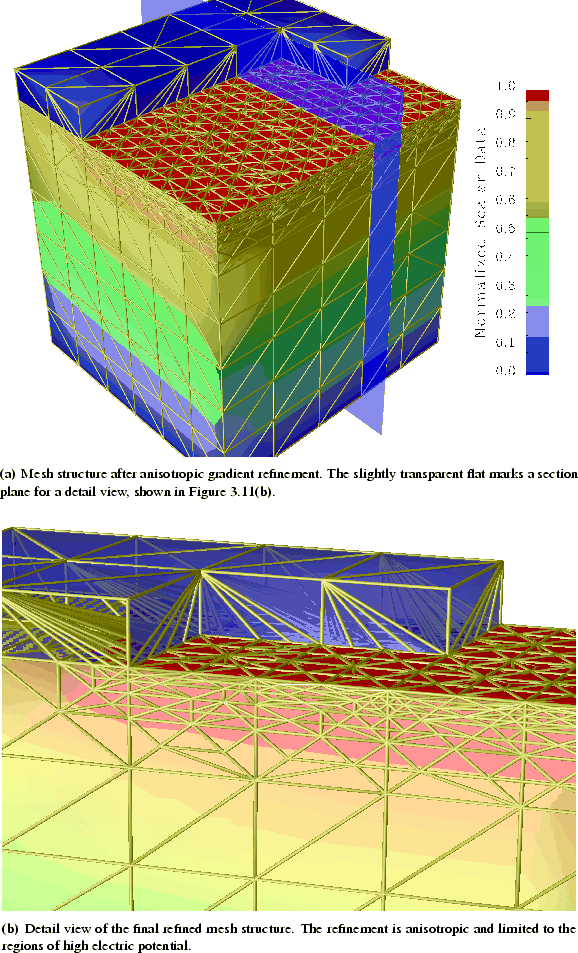 |
Figure 3.11 shows the resulting refined structure. The
refinement exhibits an excellent local behavior and covers the whole region where
the solution of the Laplace equation ![]() shows values above
shows values above ![]() of
the maximum. The anisotropy is produced
according to the orientation of the gradient field, i.e., along the gradient
direction a much higher mesh density appears, all other directions are
influenced only slightly. Other regions of the structure are kept totally
untouched. Only the mask on top is influenced by the refinement, which
is clear since the mesh conformity has to be guaranteed over the whole simulation
domain and must not be violated by the refinement procedure.
of
the maximum. The anisotropy is produced
according to the orientation of the gradient field, i.e., along the gradient
direction a much higher mesh density appears, all other directions are
influenced only slightly. Other regions of the structure are kept totally
untouched. Only the mask on top is influenced by the refinement, which
is clear since the mesh conformity has to be guaranteed over the whole simulation
domain and must not be violated by the refinement procedure.
This example closes the section about the gradient refinement method. Topic of the next section is the so-called Hessian refinement method which can be used to produce anisotropic meshes governed by the second derivatives of an initial scalar data field stored on the mesh.