|
|
|
|
Previous: 5.2 Optimization Framework Up: 5.2 Optimization Framework Next: 5.3 Gradient Based Optimization Methods |
|
|
|
|
Previous: 5.2 Optimization Framework Up: 5.2 Optimization Framework Next: 5.3 Gradient Based Optimization Methods |
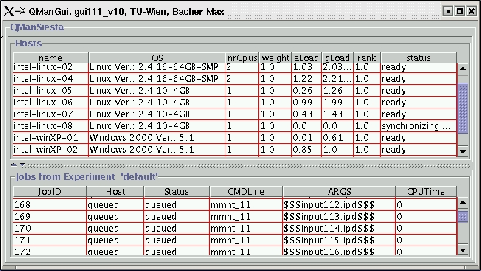
SIESTA uses a sophisticated job farming facility (QUEUE-MANAGER) [92] that utilizes the available computing power of a heterogeneous cluster of workstations. The algorithm to distribute the jobs takes care not to overload a host by using an adjustable load limit. Hosts are temporarily disabled when another started job would exceed that limit.
To choose among all available hosts, the hosts are ranked according
to their relative speed (derived from the CPU speed), to their current load
(i.e., the number of currently executing jobs), and to their number of
CPUs. The host that is assumed to finish a job fastest -- the one with
the smallest rank -- is chosen for the next job in the queue. This allows for
the combination of hosts with different CPU speeds. Since a started job is
not immediately reflected in the system load, this measure cannot directly be
used to compute the rank or the workload of the cluster would oscillate.
Therefore, a modified load, the so called guess load, is used instead. The guess
load is an estimation of the actual load which is computed by superimposing the
system load (![]() ), the number of jobs already running (
), the number of jobs already running (![]() ), and the
number of recently finished jobs (
), and the
number of recently finished jobs (![]() ) [92]
) [92]
![$\displaystyle l_{guess} = l_{base} + l_{sys} + \underbrace{\sum_{i=1}^{N} {e^{-...
...ight) \cdot{e^{-\frac{t -t_i^{stop}}{\tau_{stop}}}}\right]}}_{\rm stopped~jobs}$](img158.png) |
(5.4) |
![$\displaystyle R_i = \frac{\ensuremath{\max\left[\frac{l_{guess} +1}{n_i^{cpu}}, 1\right]}}{s_i}$](img164.png) |
(5.5) |
SIESTA is realized by linking the GUI components against the LISP system. Automatically generated language bindings [93,94,95] allow the seamless use of graphics components (written in the language C) from within the LISP language. Although this concept seems very practical and combines the rapid prototyping advantages usually attributed to the LISP language with a graphical components library (MOTIF), it also holds major drawbacks. On the one hand these drawbacks lie in the hard to learn syntax of the LISP language itself, on the other hand a much bigger disadvantage of this integral concept is the lack of clean interfaces between the modules. It is thus very complicated if not impossible to exchange one module for another. Therefore the SIESTA framework has been redesigned and some parts of it have been reimplemented. These parts are the QUEUE-MANAGER module that takes care of distributing the jobs over the workstation cluster, and the GUI module.
The functional deficiencies that finally led to a redesign of SIESTA are:
To overcome deficiency (1) a QUEUE-MANAGER GUI that is decoupled from the application via the network protocol CORBA [49] was implemented. Information flow is bidirectional, the GUI receives data about the status of the queue and sends data about user requests like addition or removal of a host from the cluster. The GUI was implemented in the programming language JAVA [34]. JAVA is platform independent and allows for easy binary distributions of applications, which relieves the user from the need to compile the source codes. Another advantage of JAVA is the capability to run the whole GUI in a web-browser. The introduced runtime overhead of JAVA / CORBA compared to the MOTIF approach can be justified for this application, since the software contains no time critical parts. Fig. 5.6 depicts a screen shot of the new GUI.
The QUEUE-MANAGER was reimplemented to cope with drawbacks (2) to (7).
Again CORBA is used to handle the communication between the hosts
participating in the cluster and with the GUI. To handle data transfer (2)
between hosts the QUEUE-MANAGER provides a platform independent copy mechanism. The
client side invokes a CORBA method. The method opens a socket on the server
side, and attaches the requested file to the socket in a separate execution
thread. The socket number is then returned to the client who initiates a
connection to the socket, and retrieves the data from the server. Unnecessary
file copy operations (3) are avoided by using symbolic names instead of concrete
paths to physical file locations. The location of a file corresponding to a
symbolic name is stored in a central location and queried directly by the host
that needs the file. The RSH command (4) is replaced by a CORBA method
invocation. To account for different UNIX5.2 nice levels (5) a modified strategy to choose a host
is used. The nice level determines the amount of computing time a process gets
assigned. To estimate the
CPU time available to a newly started job, a number of virtual ticks ![]() that are scheduled among
that are scheduled among ![]() running jobs with nice levels
running jobs with nice levels ![]() on
machine
on
machine ![]() (with
(with ![]() CPUs) is defined as (Linux kernel sources)
CPUs) is defined as (Linux kernel sources)
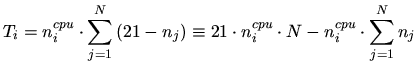 |
(5.6) |
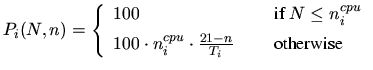 |
(5.7) |
| (5.8) |
The new implemented QUEUE-MANAGER supports the notion of groups, where an arbitrary number of jobs can be grouped together to be executed on the same machine (6). Jobs of several experiments are now queued into one QUEUE-MANAGER instance (7), the experiment that is watched in the GUI can be selected and changed at runtime.
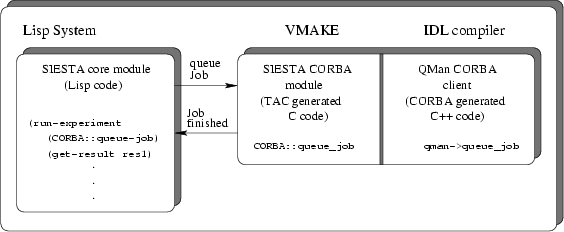
To make the new QUEUE-MANAGER work with the existing SIESTA program,
the
CORBA client of the QUEUE-MANAGER is linked against the text version
of the SIESTA LISP system (see Fig. 5.7).
To automate the binding of the C++ CORBA code to the LISP system, the Tool Abstraction Concept (TAC) of the VMAKE [87] CASE tool was used. TAC is able to semi-automatically create language bindings among the languages FORTRAN, C, and LISP. These bindings are created based on instructions that are ignored5.3 by the compiler of the target language but used by the TAC module of VMAKE.
struct HostStruct
{
string name; // name of host
short nrCpus; // nr of cpus
double limit, weight; // load limit, weight of host
double actLoad, guessLoad,
rank; // status of host
string os; // type of operating system
string status;
};
|
module QMan
{
interface ClientRequest
{
void addHost(in HostStruct ho);
void changeHost(in HostStruct ho);
void removeHost(in string name);
}
}
|
interface ClientUpdate
{
void addHost(in HostStruct ho);
void updateHost(in HostStruct ho);
void removeHost(in string name);
|
2003-03-27