|
The ever-growing demand of increased simulation complexity to better model physical phenomena requires, among other things, a combination of different simulation components. This
combination can be, for example, realized by using the output of one tool as input for another. From a software point of view, this problem can be modeled as a task graph, which is
governed by a software framework. The individual simulation tools can be seen as vertices of the task graph, which are therefore executed based on the individual task dependencies. To
improve the efficiency and therefore reduce the overall run-time of the framework, a parallelized approach for the task execution is required. A high-degree of flexibility is provided by
a distributed approach based on the Message Passing Interface (MPI), as the execution can be spread among the nodes of a large-scale cluster environment as well as on the cores of a
single workstation. In general, the distribution of parallelizable tasks among distributed and shared computing resources is a typical way to improve the overall run-time performance of a
task graph.
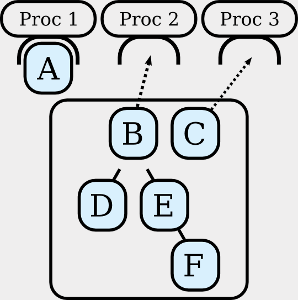
Our approach for distributing tasks on distributed computing nodes can be split into three parts. The first part is the mapping of the tasks and the corresponding dependencies on a graph
datastructure; the second, the prioritization based on the task dependences by utilizing a graph algorithm; and the third, the parallel and distributed execution on the computing nodes by
using the Boost MPI Library. The presented figure depicts the principle of the parallel execution.
We focus on a lightweight approach to implement a scheduler based on modern programming techniques, in particular, generic and functional programming in C++. By utilizing these techniques
and external libraries we are able to achieve a highly concise user-level code, by simultaneously obtaining excellent scalability with regard to the execution performance.
|